Alibaba-Tianchi NER Challenge
Published:

NER - BERT’s Downstream Task
Introduction
Named-entity recognition (NER) is a subtask of information extraction that seeks to locate and classify named entities mentioned in unstructured text into pre-defined categories such as person names, organizations, locations, medical codes, time expressions, quantities, monetary values, percentages, etc.
Task
Given a sentence of address, divide the sentence and give tag to every token. The tag including: prov(for province); city(for city); poi(for point of interest); etc.
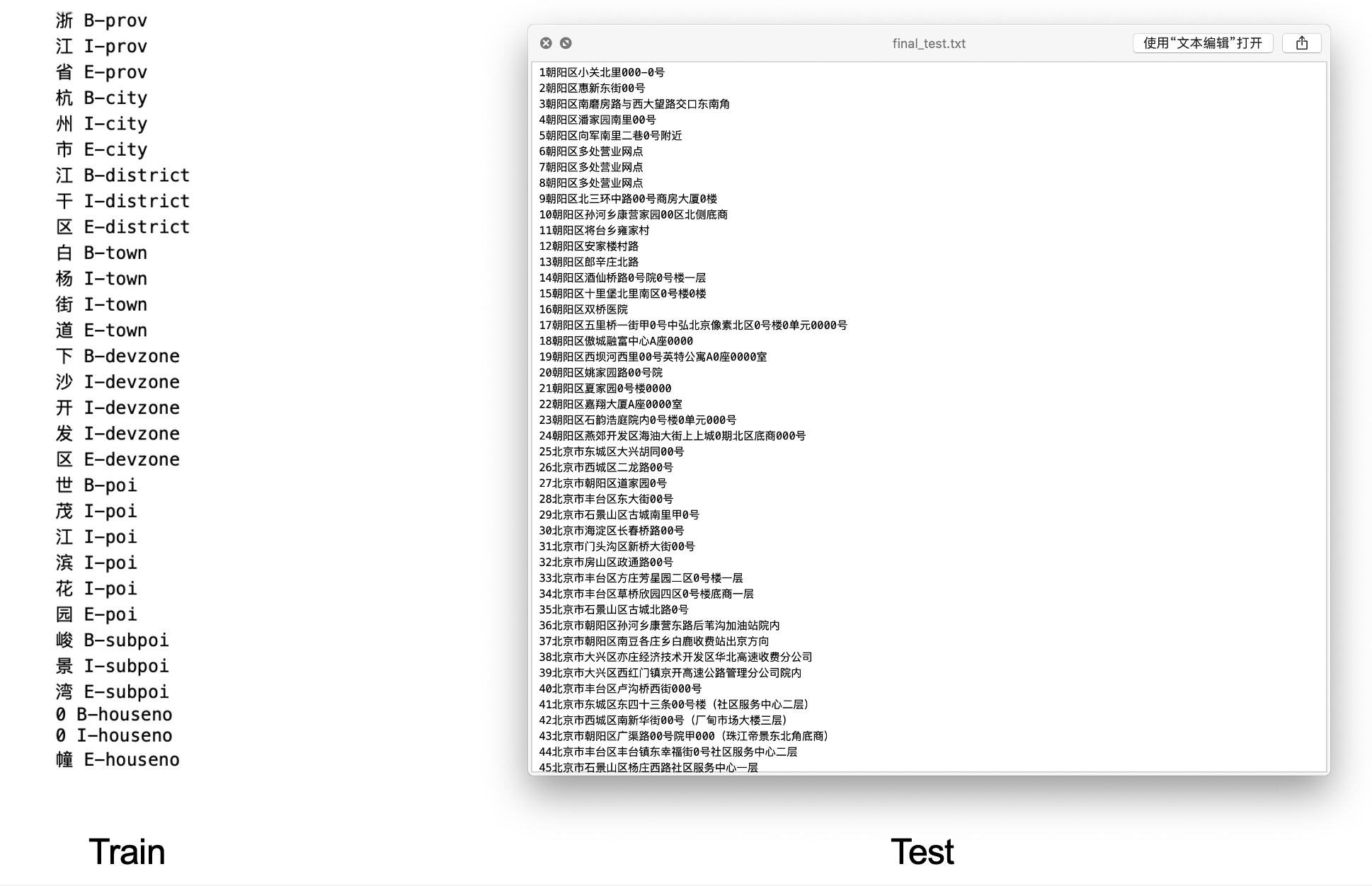
Dataset
Method
We use a pre-trained BERT model, connected it with a Single Dense Layer to get the output(classified output).
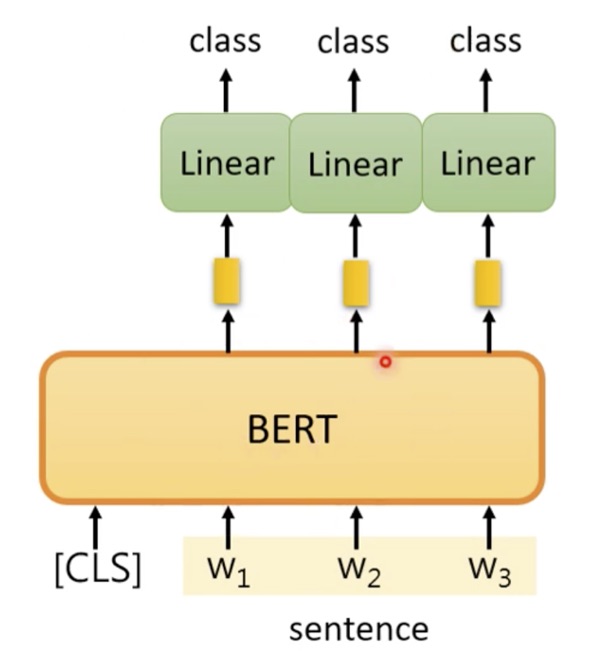
However, simple BERT model could not satisfied the performance we want.
We found that there are several limitations:
- Single Dense Layer at output of the BERT.
- No regulation for the order of the output.eg: ‘E-city B-city’ is unreasonable.(lable ‘E-city’ - End of city should be at the end of the token)
- Pre-trained BERT model is not powerful enough.
- Data Augmentation could be done.
Improve 1: BERT + CRF
CRF is a discriminant model for sequences data similar to MEMM. It models the dependency between each state and the entire input sequences. Unlike MEMM, CRF overcomes the label bias issue by using global normalizer.
We use CRF to give regulation to the output of the BERT, to solve limitation 3: unreasonable order of the predicted label. For those non-existent orders, we set the prob to -1, which make sure the model won’t predict the wrong answer.
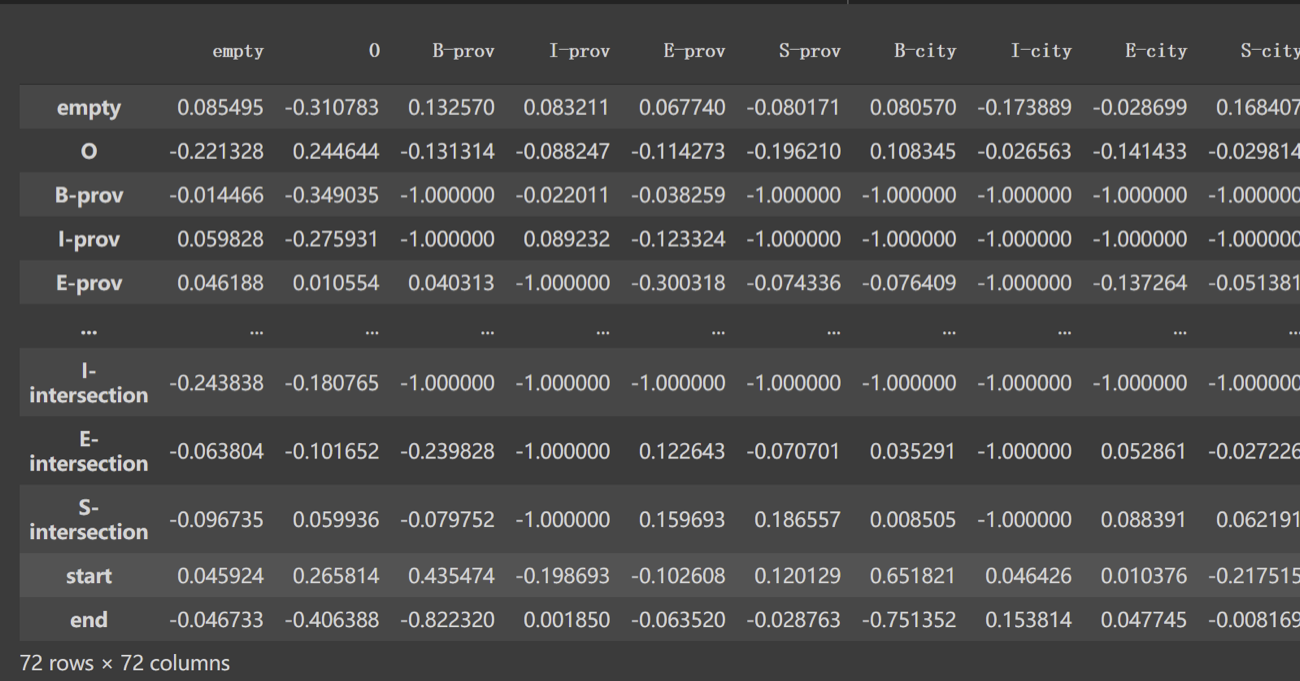
Regulation matrix of the output using CRF.
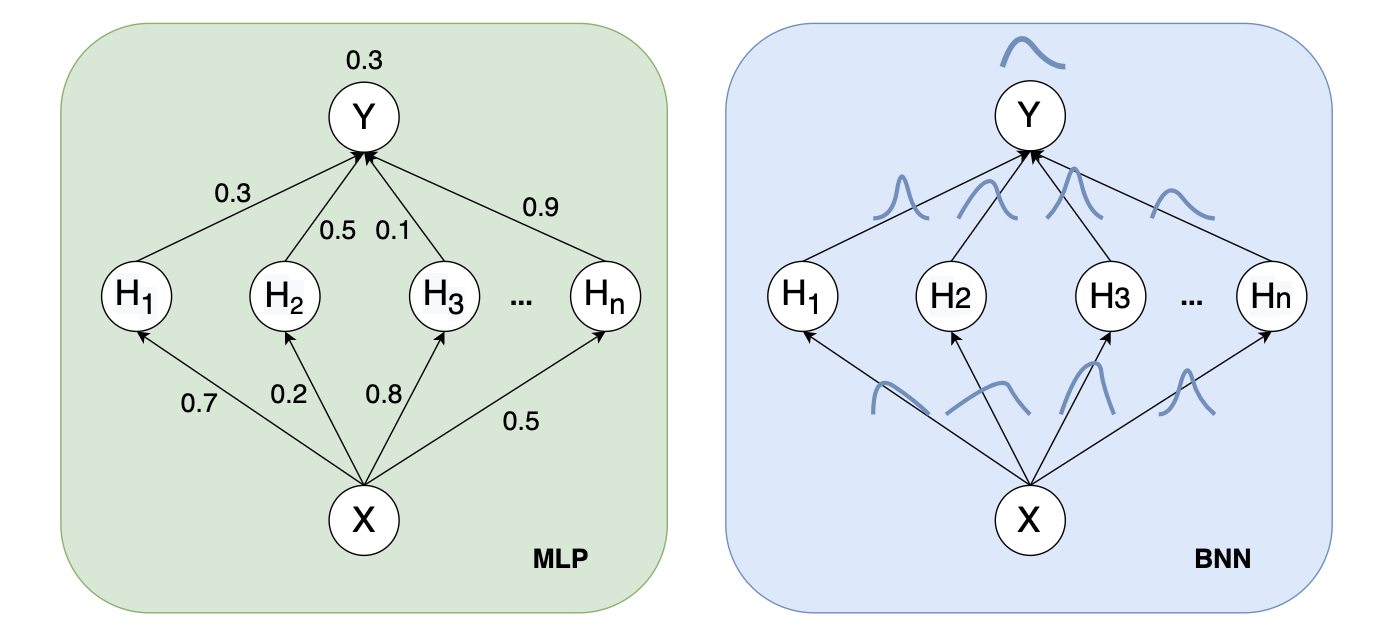
Improve 2: Dense => MLP
We use a 2-layer MLP instead of the Dense Layer.
Improve 3: Minor Changes
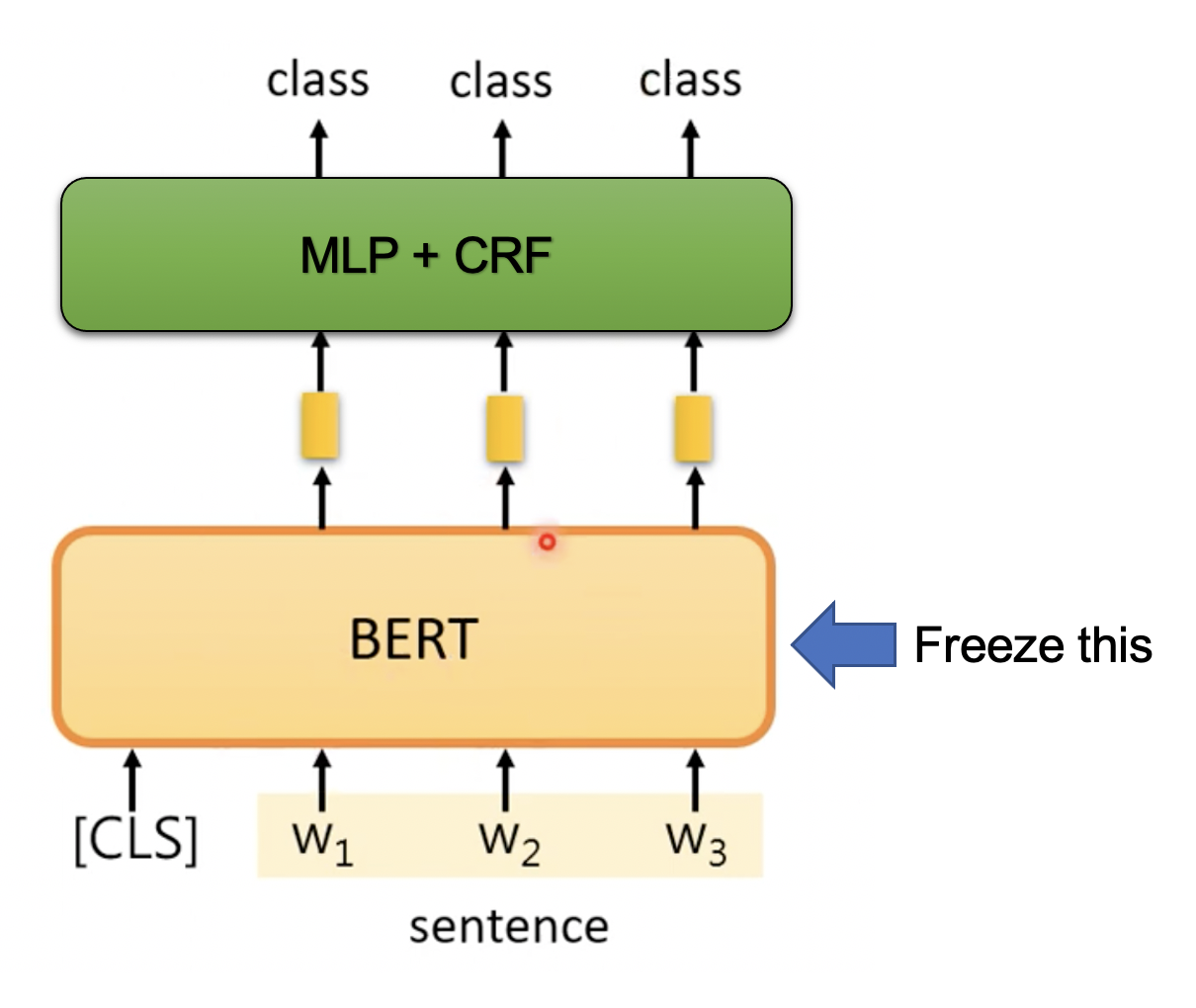
1.We freeze the weights in BERT when training, because we found that fine-tuning the BERT for this subtask(Address NER) will lead to a poor performance.
2.We use RoBERTa for pre-trained model because compared to BERT, RoBERTa has: More parameters; Larger batch size; Drop NSP when pre-training; Dynamic Mask.
3.We use [Data Augmentation with a Generation Approach for Low-resource Tagging Tasks (DAGA)] (https://ntunlpsg.github.io/publication/daga/)for data augmentation. It could generate new data with label using the existing training data.
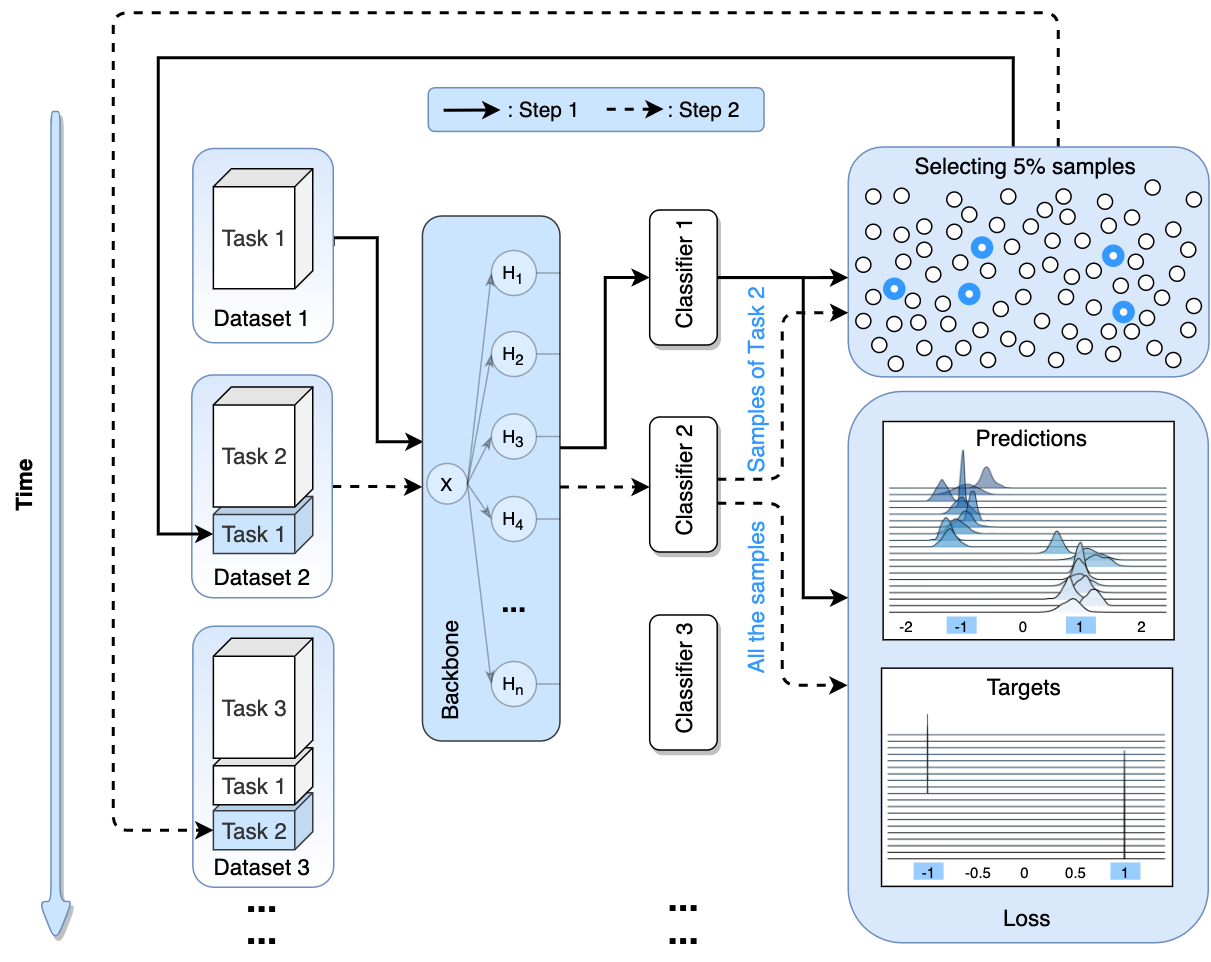
Steps of DAGA:
(1)Concatenate the data and label into one sentence.
(2)Use these data to train a LM model to generate new sentence.
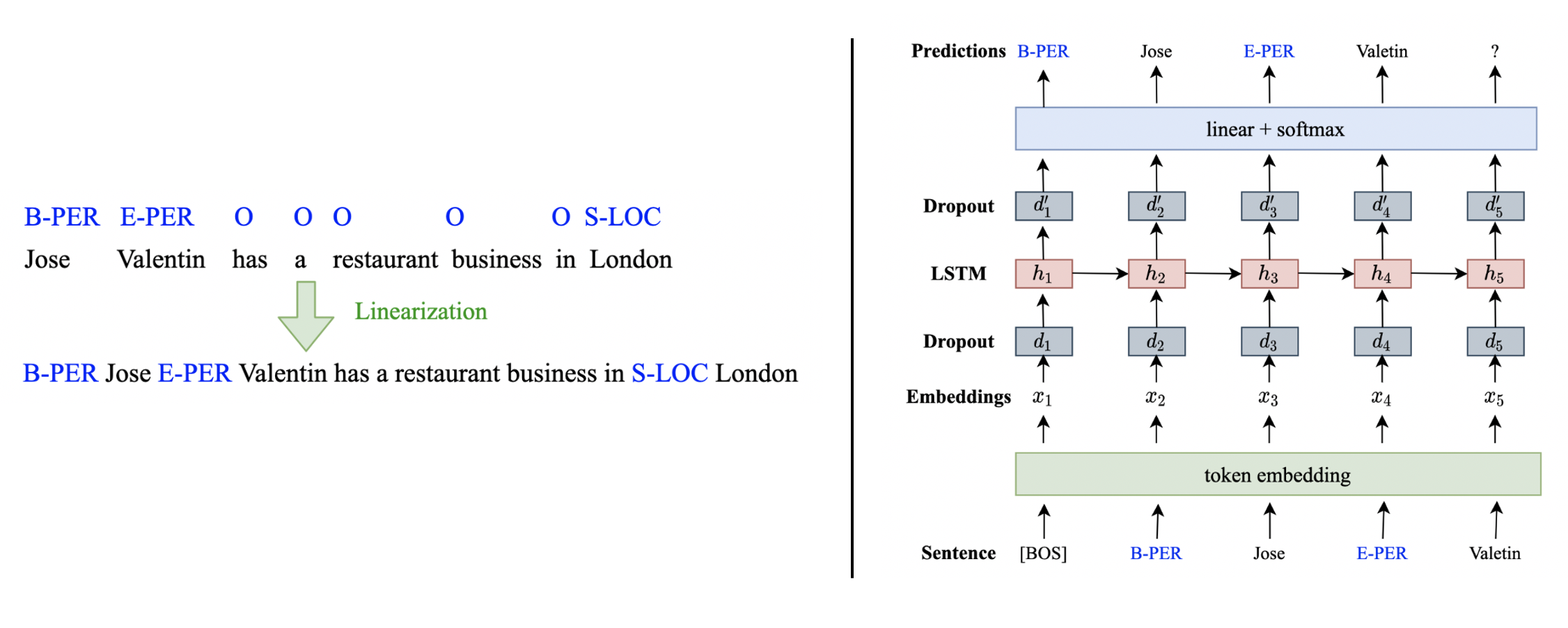
Left: step1; Right: step2.
The generated sentences:
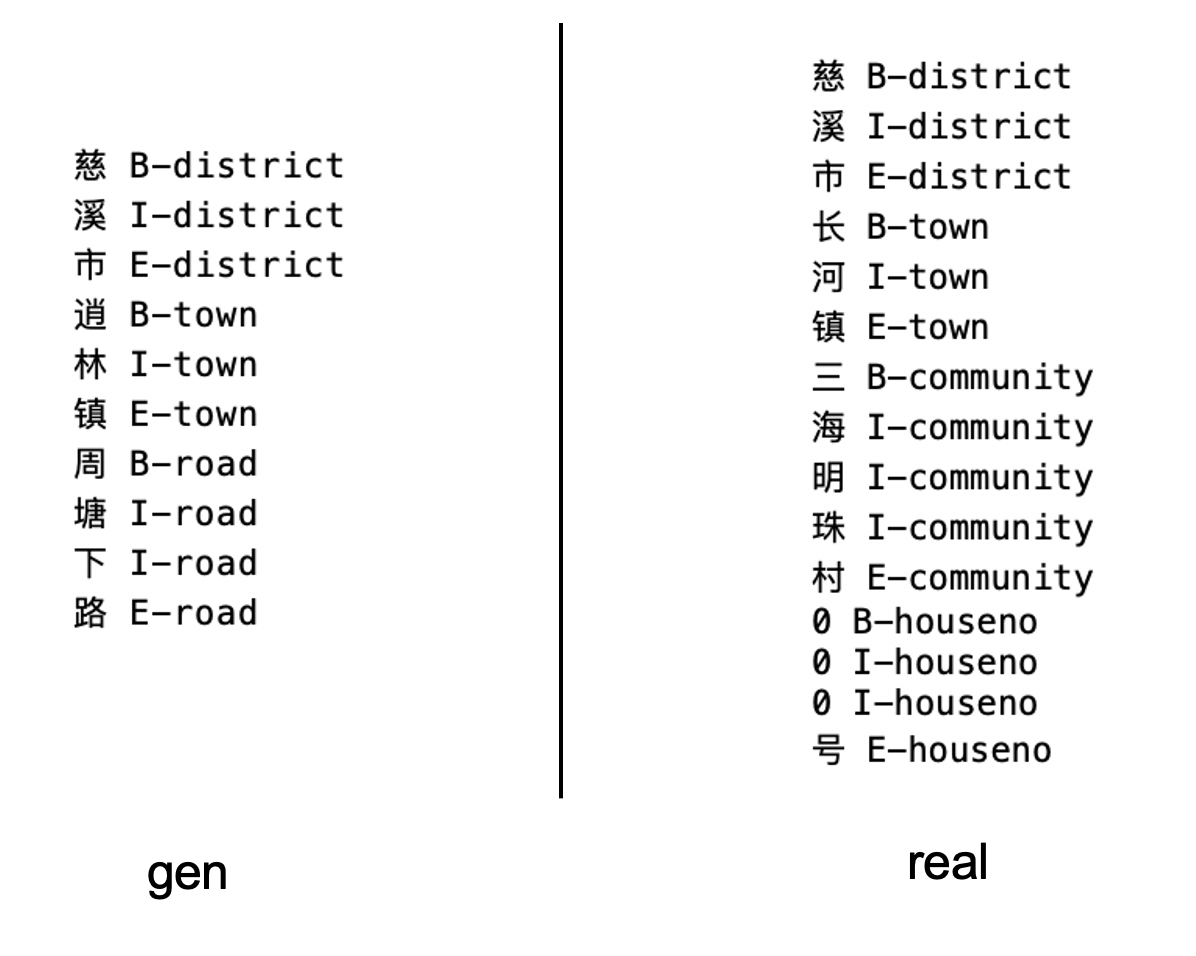
Result
We are currently ranked top 1.9%. There are 2122 teams.
Contact
The above is the a brief description of the AliTianchi Challenge. If you encounter unclear or controversial issues, feel free to contact Leslie Wong.